Recently I was asked by O’Reilly publishing to give a book review for Paul Teetor new introductory book to R. After giving the book some attention and appreciating it’s delivery of the material, I was happy to write and post this review. Also, I’m very happy to see how a major publishing house like O’Reilly is producing more and more R books, great news indeed.
And now for the book review:
Executive summary: a book that offers a well designed gentle introduction for people with some background in statistics wishing to learn how to get common (basic) tasks done with R.
Information
By: Paul Teetor Publisher:O’Reilly MediaReleased: January 2011 Pages: 58 (est.)
Format
The book “25 Recipes for Getting Started with R” offers an interesting take on how to bring R to the general (statistically oriented) public.
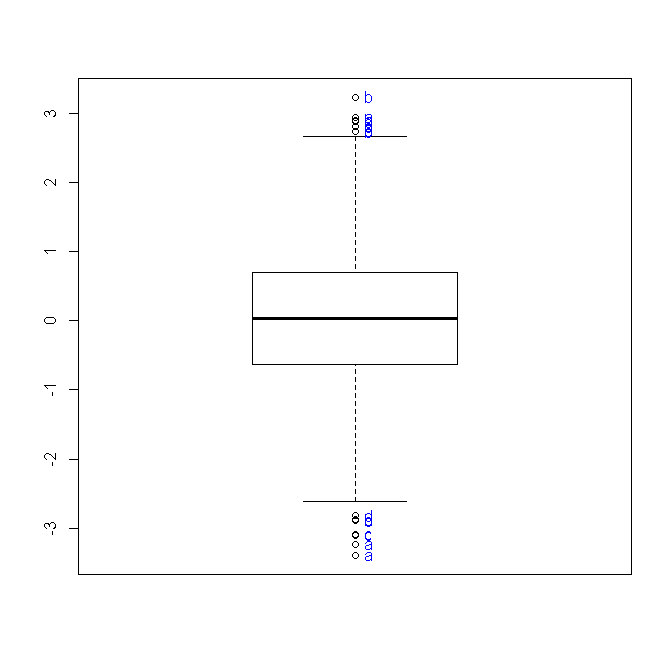
In this post I offer an alternative function for boxplot, which will enable you to label outlier observations while handling complex uses of boxplot.
In this post I present a function that helps to label outlier observations When plotting a boxplot using R.
An outlier is an observation that is numerically distant from the rest of the data. When reviewing a boxplot, an outlier is defined as a data point that is located outside the fences (“whiskers”) of the boxplot (e.g: outside 1.5 times the interquartile range above the upper quartile and bellow the lower quartile).
Identifying these points in R is very simply when dealing with only one boxplot and a few outliers. That can easily be done using the “identify” function in R. For example, running the code bellow will plot a boxplot of a hundred observation sampled from a normal distribution, and will then enable you to pick the outlier point and have it’s label (in this case, that number id) plotted beside the point:
set.seed(482)
y <- rnorm(100)
boxplot(y)
identify(rep(1, length(y)), y, labels = seq_along(y))
However, this solution is not scalable when dealing with:
Many outliers
Overlapping data-points, and
Multiple boxplots in the same graphic window
For such cases I recently wrote the function "boxplot.with.outlier.label" (which you can download from here). This function will plot operates in a similar way as "boxplot" (formula) does, with the added option of defining "label_name". When outliers are presented, the function will then progress to mark all the outliers using the label_name variable. This function can handle interaction terms and will also try to space the labels so that they won't overlap (my thanks goes to Greg Snow for his function "spread.labs" from the {TeachingDemos} package, and helpful comments in the R-help mailing list).
Here is some example code you can try out for yourself:
source("https://raw.githubusercontent.com/talgalili/R-code-snippets/master/boxplot.with.outlier.label.r") # Load the function
# sample some points and labels for us:
set.seed(492)
y <- rnorm(2000)
x1 <- sample(letters[1:2], 2000,T)
x2 <- sample(letters[1:2], 2000,T)
lab_y <- sample(letters[1:4], 2000,T)
# plot a boxplot with interactions:
boxplot.with.outlier.label(y~x2*x1, lab_y)
Here is the resulting graph:
You can also have a try and run the following code to see how it handles simpler cases:
# plot a boxplot without interactions:
boxplot.with.outlier.label(y~x1, lab_y, ylim = c(-5,5))
# plot a boxplot of y only
boxplot.with.outlier.label(y, lab_y, ylim = c(-5,5))
boxplot.with.outlier.label(y, lab_y, spread_text = F) # here the labels will overlap (because I turned spread_text off)
Here is the output of the last example, showing how the plot looks when we allow for the text to overlap (we would often prefer to NOT allow it).
Regarding package dependencies: notice that this function requires you to first install the packages {TeachingDemos} (by Greg Snow) and {plyr} (by Hadley Wickham)
Updates: 19.04.2011 - I've added support to the boxplot "names" and "at" parameters.
You are very much invited to leave your comments if you find a bug, think of ways to improve the function, or simply enjoyed it and would like to share it with me.
Rob Calver wrote an interesting invitation on the R mailing list today, inviting potential authors to submit their vision of the next great book about R. The announcement originated from the Chapman & Hall/CRC publishing houses, backed up by an impressive team of R celebrities, chosen as the editors of this new R books series, including:
A year ago (on December 9th 2009), I wrote about founding R-bloggers.com, an (unofficial) online R journal written by bloggers who agreed to contribute their R articles to the site.
In this post I wish to celebrate R-bloggers’ first birthday by sharing with you:
Links to the top 14 posts of 2010
Reflections about the origin of R-bloggers
Statistics on “how well” R-bloggers did this year
Links to other related projects
An invitation for sponsors/supporters to help keep the site alive
John Fox is (very) well known in the R community for many contributions to R, including the car package (which any one who is interested in performing SS type II and III repeated measures anova in R, is sure to come by), the Rcmdr pacakge (one of the two major GUI’s for R, the second one is Deducer), sem (for Structural Equation Models) and more. These might explain why I think having him release a new edition for his book to be big news for the R community of users.
In this new edition, Professor Fox has teamed with Professor Sandy Weisberg, to refresh the original edition so to cover the development gained in the (nearly) 10 years since the first edition was written.
Here is what John Fox had to say:
Dear all,
Sandy Weisberg and I would like to announce the publication of the second edition of An R Companion to Applied Regression (Sage, 2011).
As is immediately clear, the book now has two authors and S-PLUS is gone from the title (and the book). The R Companion has also been thoroughly rewritten, covering developments in the nearly 10 years since the first edition was written and expanding coverage of topics such as R graphics and R programming. As before, however, the R Companion provides a general introduction to R in the context of applied regression analysis, broadly construed. It is available from the publisher at (US) or (UK), and from Amazon (see here)
The book is augmented by a web site with data sets, appendices on a variety of topics, and more, and it associated with the car package on CRAN, which has recently undergone an overhaul.
Earlier today, Ian Fwllows has announced the release of Deducer 0.4-2 and DeducerExtras 1.2 to CRAN (I copy his announcement here): Deducer 0.4-2 contains a few bug fixes, and an interface to the iplots package. With the new iplots interface it is now possible to do interactive plots with Deducer. An introductory example screen cast (by Ian) is available on the tube:
DeducerExtras 1.2 contains a few new dialogs including ‘load data from package’, and ‘t-test power’.
Additionally, a new Windows R/JGR/Deducer installer is available which installs R-2.12.0, JGR with it’s launcher, Deducer, DeducerExtras, and DeducerPlugInScaling. It is available on the Deducer website: http://www.deducer.org/pmwiki/pmwiki.php?n=Main.WindowsInstallation
Today I was informed of (what I believe is) a better the best WordPress plugin for R syntax highlighting called WP-CodeBox. This plugin doesn’t require any hacks to make it work (as opposed to the WP-Syntax plugin, which I wrote about in the past). WP-CodeBox can be downloaded and installed on a WordPress by searching for it in the “Add New” section in the plugins menu.
WP-CodeBox provides some nice features (some AJAX based) to the display of the code in the post:
The code box in the post can now be folded (top right of the code box) so the code can be hidden so to not clutter the post (if the code is too long)
The code box is added with another button (top left of the code box) which allows the reader to see the code in a new window – so to easily enable a copy paste of the code.
The options of the plugin allows automatic row numbering of the code, control over “tab” length and some other features.
The ff package provides data structures that are stored on disk but behave (almost) as if they were in RAM by transparently mapping only a section (pagesize) in main memory – the effective virtual memory consumption per ff object.
Here are the new features of ff, as Jens wrote in his announcement:
—- Dear R community,
The next release of package ff is available on CRAN. With kind help of Brian Ripley it now supports the Win64 and Sun versions of R. It has three major functional enhancements:
a) new fast in-memory sorting and ordering functions (single-threaded) b) ff now supports on-disk sorting and ordering of ff vectors and ffdf dataframes c) ff integer vectors now can be used as subscripts of ff vectors and ffdf dataframes
a) is achieved by careful implementation of NA-handling and exploiting context information b) although permanently stored, sorting and ordering of ff objects can be faster than the standard routines in R c) applying an order to ff vectors and ffdf dataframes is substantially slower than in pure R because it involves disk-access AND sorting index positions (to avoid random access).
There is still room for improvement, however, the current status should already be useful. I run some comparisons with SAS (see end of mail): – both could sort German census size (81e6 rows) on a 3GB notebook – ff sorts and orders faster on single columns – sorting big multicolumn-tables is faster in SAS


")
")
