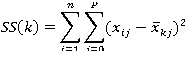Joint post by Yoav Benjamini and Tal Galili. The post highlights points raised by Yoav in his official response to the ASA statement (available as on page 4 in the ASA supplemental tab), as well as offers a list of relevant R resources.
Summary
The ASA statement about the misuses of the p-value singles it out. It is just as well relevant to the use of most other statistical methods: context matters, no single statistical measure suffices, specific thresholds should be avoided and reporting should not be done selectively. The latter problem is discussed mainly in relation to omitted inferences. We argue that the selective reporting of inferences problem is serious enough a problem in our current industrialized science even when no omission takes place. Many R tools are available to address it, but they are mainly used in very large problems and are grossly underused in areas where lack of replicability hits hard.
David Donoho published a fascinating paper based on a presentation at the Tukey Centennial workshop, Princeton NJ Sept 18 2015. You can download the full paper from here.
More than 50 years ago, John Tukey called for a reformation of academic statistics. In ‘The Future of Data Analysis’, he pointed to the existence of an as-yet unrecognized science, whose subject of interest was learning from data, or ‘data analysis’. Ten to twenty years ago, John Chambers, Bill Cleveland and Leo Breiman independently once again urged academic statistics to expand its boundaries beyond the classical domain of theoretical statistics; Chambers called for more emphasis on data preparation and presentation rather than statistical modeling; and Breiman called for emphasis on prediction rather than inference. Cleveland even suggested the catchy name “Data Science” for his envisioned field.
A recent and growing phenomenon is the emergence of “Data Science” programs at major universities, including UC Berkeley, NYU, MIT, and most recently the Univ. of Michigan, which on September 8, 2015 announced a $100M “Data Science Initiative” that will hire 35 new faculty. Teaching in these new programs has significant overlap in curricular subject matter with traditional statistics courses; in general, though, the new initiatives steer away from close involvement with academic statistics departments.
This paper reviews some ingredients of the current “Data Science moment”, including recent commentary about data science in the popular media, and about how/whether Data Science is really different from Statistics.
The now-contemplated field of Data Science amounts to a superset of the fields of statistics and machine learning which adds some technology for ‘scaling up’ to ‘big data’. This chosen superset is motivated by commercial rather than intellectual developments. Choosing in this way is likely to miss out on the really important intellectual event of the next fifty years.
Because all of science itself will soon become data that can be mined, the imminent revolution in Data Science is not about mere ‘scaling up’, but instead the emergence of scientific studies of data analysis science-wide. In the future, we will be able to predict how a proposal to change data analysis workflows would impact the validity of data analysis across all of science, even predicting the impacts field-by-field. Drawing on work by Tukey, Cleveland, Chambers and Breiman, I present a vision of data science based on the activities of people who are ‘learning from data’, and I describe an academic field dedicated to improving that activity in an evidence-based manner. This new field is a better academic enlargement of statistics and machine learning than today’s Data Science Initiatives, while being able to accommodate the same short-term goals.
Contents
1 Today’s Data Science Moment
2 Data Science ‘versus’ Statistics
2.1 The ‘Big Data’ Meme
2.2 The ‘Skills’ Meme
2.3 The ‘Jobs’ Meme
2.4 What here is real?
2.5 A Better Framework
3 The Future of Data Analysis, 1962
4 The 50 years since FoDA
4.1 Exhortations
4.2 Reification
5 Breiman’s ‘Two Cultures’, 2001
6 The Predictive Culture’s Secret Sauce
6.1 The Common Task Framework
6.2 Experience with CTF
6.3 The Secret Sauce
6.4 Required Skills
7 Teaching of today’s consensus Data Science
8 The Full Scope of Data Science
8.1 The Six Divisions
8.2 Discussion
8.3 Teaching of GDS
8.4 Research in GDS
8.4.1 Quantitative Programming Environments: R
8.4.2 Data Wrangling: Tidy Data
8.4.3 Research Presentation: Knitr
8.5 Discussion
9 Science about Data Science
9.1 Science-Wide Meta Analysis
9.2 Cross-Study Analysis
9.3 Cross-Workflow Analysis
9.4 Summary
10 The Next 50 Years of Data Science
10.1 Open Science takes over
10.2 Science as data
10.3 Scientific Data Analysis, tested Empirically
10.3.1 DJ Hand (2006)
10.3.2 Donoho and Jin (2008)
10.3.3 Zhao, Parmigiani, Huttenhower and Waldron (2014)
Guest post by Gergely Daróczi. If you like this content, you can buy the full 396 paged e-book for 5 USD until January 8, 2016 as part of Packt’s “$5 Skill Up Campaign” at https://bit.ly/mastering-R
Feature extraction tends to be one of the most important steps in machine learning and data science projects, so I decided to republish a related short section from my intermediate book on how to analyze data with R. The 9th chapter is dedicated to traditional dimension reduction methods, such as Principal Component Analysis, Factor Analysis and Multidimensional Scaling — from which the below introductory examples will focus on that latter.
Multidimensional Scaling (MDS) is a multivariate statistical technique first used in geography. The main goal of MDS it is to plot multivariate data points in two dimensions, thus revealing the structure of the dataset by visualizing the relative distance of the observations. Multidimensional scaling is used in diverse fields such as attitude study in psychology, sociology or market research.
Although the MASS package provides non-metric methods via the isoMDS function, we will now concentrate on the classical, metric MDS, which is available by calling the cmdscale function bundled with the stats package. Both types of MDS take a distance matrix as the main argument, which can be created from any numeric tabular data by the dist function.
But before such more complex examples, let’s see what MDS can offer for us while working with an already existing distance matrix, like the built-in eurodist dataset:
> as.matrix(eurodist)[1:5, 1:5]
Athens Barcelona Brussels Calais Cherbourg
Athens 0 3313 2963 3175 3339
Barcelona 3313 0 1318 1326 1294
Brussels 2963 1318 0 204 583
Calais 3175 1326 204 0 460
Cherbourg 3339 1294 583 460 0
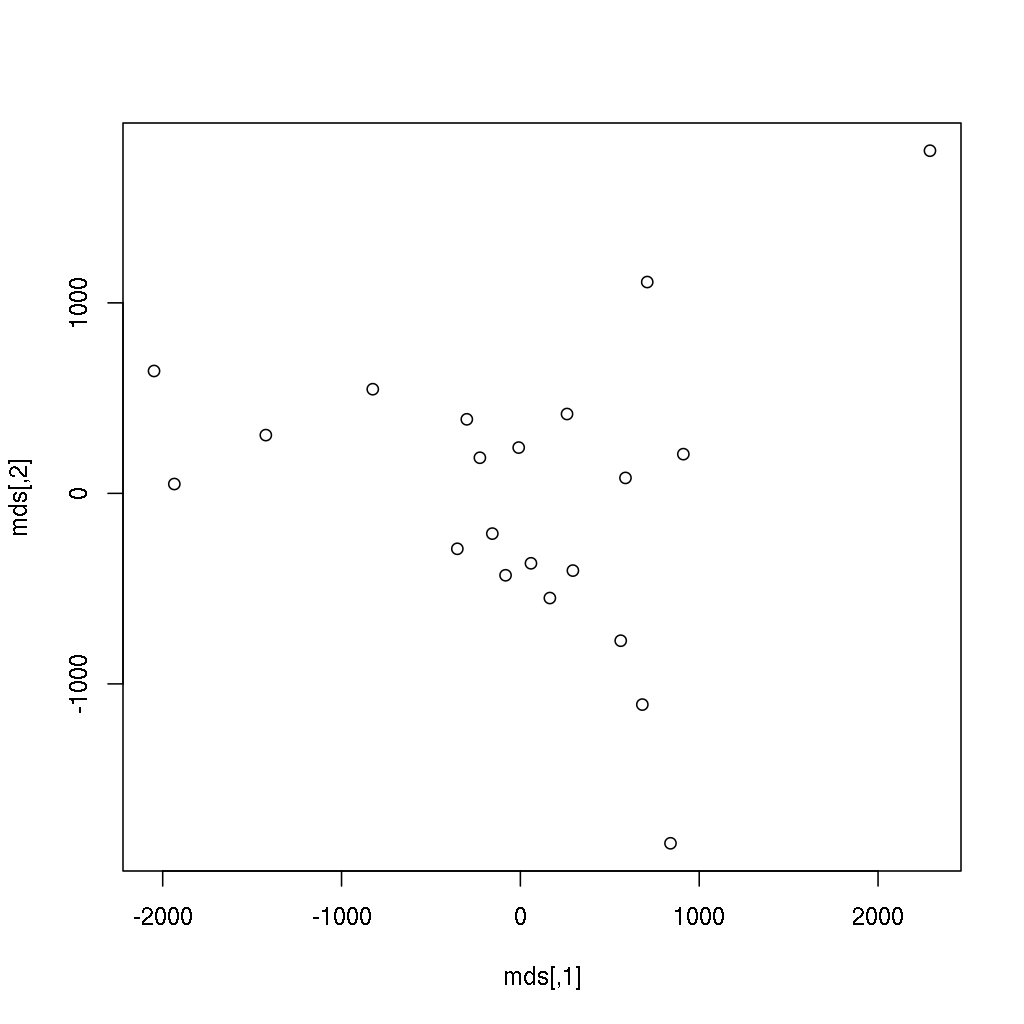
The above subset (first 5-5 values) of the distance matrix represents the travel distance between 21 European cities in kilometers. Running classical MDS on this example returns:
> (mds <- cmdscale(eurodist))
[,1] [,2]
Athens 2290.2747 1798.803
Barcelona -825.3828 546.811
Brussels 59.1833 -367.081
Calais -82.8460 -429.915
Cherbourg -352.4994 -290.908
Cologne 293.6896 -405.312
Copenhagen 681.9315 -1108.645
Geneva -9.4234 240.406
Gibraltar -2048.4491 642.459
Hamburg 561.1090 -773.369
Hook of Holland 164.9218 -549.367
Lisbon -1935.0408 49.125
Lyons -226.4232 187.088
Madrid -1423.3537 305.875
Marseilles -299.4987 388.807
Milan 260.8780 416.674
Munich 587.6757 81.182
Paris -156.8363 -211.139
Rome 709.4133 1109.367
Stockholm 839.4459 -1836.791
Vienna 911.2305 205.930
These scores are very similar to two principal components (discussed in the previous, Principal Component Analysis section), such as running prcomp(eurodist)$x[, 1:2]. As a matter of fact, PCA can be considered as the most basic MDS solution.
Anyway, we have just transformed (reduced) the 21-dimensional space into 2 dimensions, which can be plotted very easily — unlike the original distance matrix with 21 rows and 21 columns:
> plot(mds)
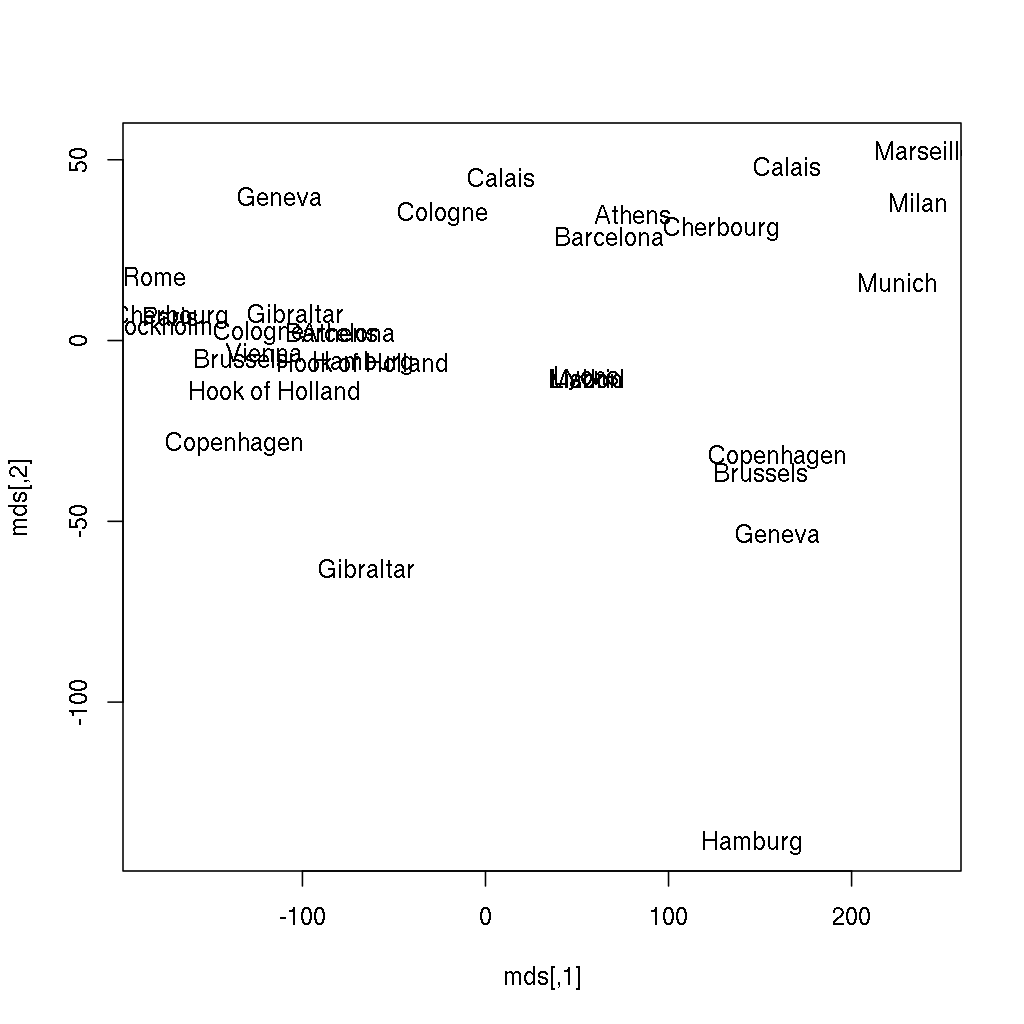
Does it ring a bell? If not yet, the below image might be more helpful, where the following two lines of code also renders the city names instead of showing anonymous points:
p.s.: Yes – this presentation is very similar, although not identical, to the one I gave at useR2015. For example, I mention the new bioinformatics paper on dendextend.
Summary:dendextend is an R package for creating and comparing visually appealing tree diagrams. dendextend provides utility functions for manipulating dendrogram objects (their color, shape, and content) as well as several advanced methods for comparing trees to one another (both statistically and visually). As such, dendextend offers a flexible framework for enhancing R’s rich ecosystem of packages for performing hierarchical clustering of items.
In R’s partitioning approach, observations are divided into K groups and reshuffled to form the most cohesive clusters possible according to a given criterion. There are two methods—K-means and partitioning around mediods (PAM). In this article, based on chapter 16 of R in Action, Second Edition, author Rob Kabacoff discusses K-means clustering.
In R’s partitioning approach, observations are divided into K groups and reshuffled to form the most cohesive clusters possible according to a given criterion. There are two methods—K-means and partitioning around mediods (PAM). In this article, based on chapter 16 of R in Action, Second Edition, author Rob Kabacoff discusses K-means clustering.
Until Aug 21, 2013, you can buy the book: R in Action, Second Edition with a 44% discount, using the code: “mlria2bl”.
K-means clustering
The most common partitioning method is the K-means cluster analysis. Conceptually, the K-means algorithm:
Selects K centroids (K rows chosen at random)
Assigns each data point to its closest centroid
Recalculates the centroids as the average of all data points in a cluster (i.e., the centroids are p-length mean vectors, where p is the number of variables)
Assigns data points to their closest centroids
Continues steps 3 and 4 until the observations are not reassigned or the maximum number of iterations (R uses 10 as a default) is reached.
Implementation details for this approach can vary.
R uses an efficient algorithm by Hartigan and Wong (1979) that partitions the observations into k groups such that the sum of squares of the observations to their assigned cluster centers is a minimum. This means that in steps 2 and 4, each observation is assigned to the cluster with the smallest value of:
Where k is the cluster,xij is the value of the jth variable for the ith observation, and xkj-bar is the mean of the jth variable for the kth cluster.
Disclaimer: This post is not intended to be a comprehensive review, but more of a “getting started guide”. If I did not mention an important tool or package I apologize, and invite readers to contribute in the comments.
Introduction
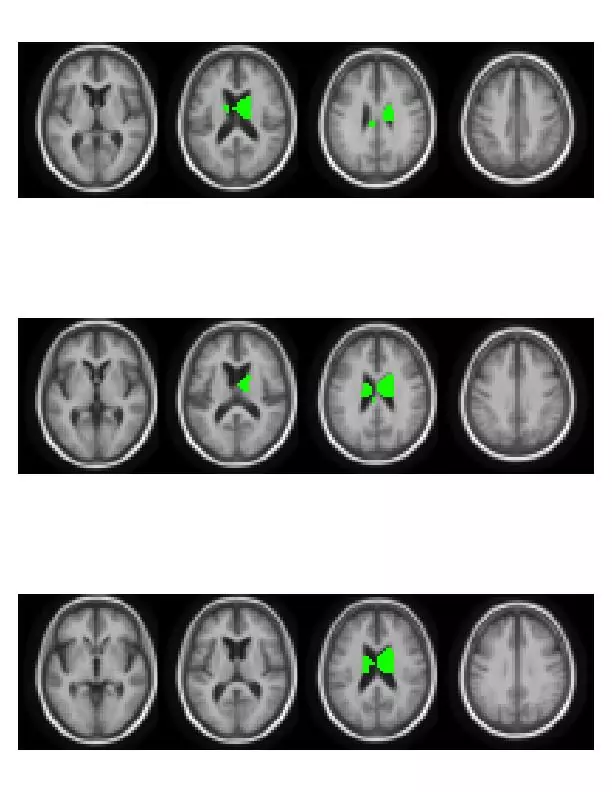
I have recently had the delight to participate in a “Brain Hackathon” organized as part of the OHBM2013 conference. Being supported by Amazon, the hackathon participants were provided with Amazon credit in order to promote the analysis using Amazon’s Web Services (AWS). We badly needed this computing power, as we had 14*109 p-values to compute in order to localize genetic associations in the brain leading to Figure 1.
Figure 1- Brain volumes significantly associated to genotype.
While imaging genetics is an interesting research topic, and the hackathon was a great idea by itself, it is the AWS I wish to present in this post. Starting with the conclusion:
Storing your data and analyzing it on the cloud, be it AWS, Azure, Rackspace or others, is a quantum leap in analysis capabilities. I fell in love with my new cloud powers and I strongly recommend all statisticians and data scientists get friendly with these services. I will also note that if statisticians do not embrace these new-found powers, we should not be surprised if data analysis becomes synonymous with Machine Learning and not with Statistics (if you have no idea what I am talking about, read this excellent post by Larry Wasserman).
As motivation for analysis in the cloud consider:
The ability to do your analysis from any device, be it a PC, tablet or even smartphone.
The ability to instantaneously augment your CPU and memory to any imaginable configuration just by clicking a menu. Then scaling down to save costs once you are done.
The ability to instantaneously switch between operating systems and system configurations.
The ability to launch hundreds of machines creating your own cluster, parallelizing your massive job, and then shutting it down once done.
Here is a quick FAQ before going into the setup stages.
This is a guest article by Nina Zumel and John Mount, authors of the new book Practical Data Science with R. For readers of this blog, there is a 50% discount offthe “Practical Data Science with R” book, simply by using the code pdswrblo when reaching checkout (until the 30th this month). Here is the post:
Normalizing data by mean and standard deviation is most meaningful when the data distribution is roughly symmetric. In this article, based on chapter 4 of Practical Data Science with R, the authors show you a transformation that can make some distributions more symmetric.
The need for data transformation can depend on the modeling method that you plan to use. For linear and logistic regression, for example, you ideally want to make sure that the relationship between input variables and output variables is approximately linear, that the input variables are approximately normal in distribution, and that the output variable is constant variance (that is, the variance of the output variable is independent of the input variables). You may need to transform some of your input variables to better meet these assumptions.
In this article, we will look at some log transformations and when to use them.
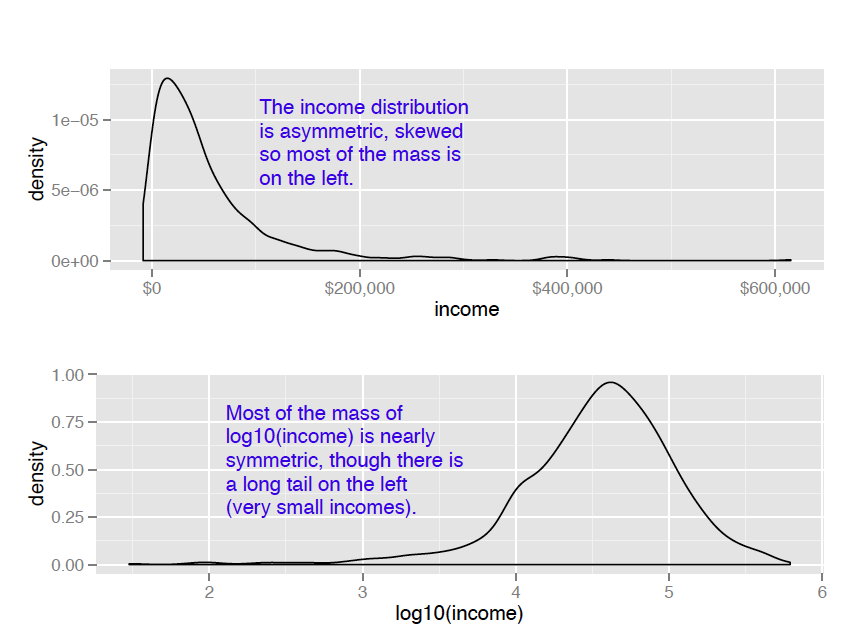
Monetary amounts—incomes, customer value, account or purchase sizes—are some of the most commonly encountered sources of skewed distributions in data science applications. In fact, as we discuss in Appendix B: Important Statistical Concepts, monetary amounts are often lognormally distributed—that is, the log of the data is normally distributed. This leads us to the idea that taking the log of the data can restore symmetry to it. We demonstrate this in figure 1.
Figure 1 A nearly lognormal distribution, and its log
For the purposes of modeling, which logarithm you use—natural logarithm, log base 10 or log base 2—is generally not critical. In regression, for example, the choice of logarithm affects the magnitude of the coefficient that corresponds to the logged variable, but it doesn’t affect the value of the outcome. I like to use log base 10 for monetary amounts, because orders of ten seem natural for money: $100, $1000, $10,000, and so on. The transformed data is easy to read.
An aside on graphing
The difference between using the ggplot layer scale_x_log10 on a densityplot of income and plotting a densityplot of log10(income) is primarily axis labeling. Using scale_x_log10 will label the x-axis in dollars amounts, rather than in logs.
It’s also generally a good idea to log transform data with values that range over several orders of magnitude. First, because modeling techniques often have a difficult time with very wide data ranges, and second, because such data often comes from multiplicative processes, so log units are in some sense more natural.
For example, when you are studying weight loss, the natural unit is often pounds or kilograms. If I weigh 150 pounds, and my friend weighs 200, we are both equally active, and we both go on the exact same restricted-calorie diet, then we will probably both lose about the same number of pounds—in other words, how much weight we lose doesn’t (to first order) depend on how much we weighed in the first place, only on calorie intake. This is an additive process.
On the other hand, if management gives everyone in the department a raise, it probably isn’t by giving everyone $5000 extra. Instead, everyone gets a 2 percent raise: how much extra money ends up in my paycheck depends on my initial salary. This is a multiplicative process, and the natural unit of measurement is percentage, not absolute dollars. Other examples of multiplicative processes: a change to an online retail site increases conversion (purchases) for each item by 2 percent (not by exactly two purchases); a change to a restaurant menu increases patronage every night by 5 percent (not by exactly five customers every night). When the process is multiplicative, log-transforming the process data can make modeling easier.
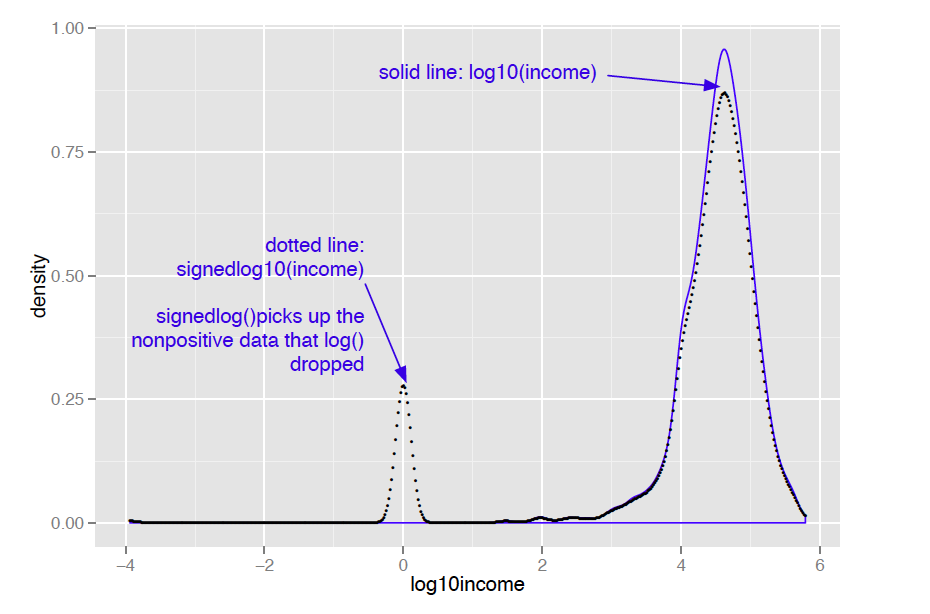
Of course, taking the logarithm only works if the data is non-negative. There are other transforms, such as arcsinh, that you can use to decrease data range if you have zero or negative values. I don’t like to use arcsinh, because I don’t find the values of the transformed data to be meaningful. In applications where the skewed data is monetary (like account balances or customer value), I instead use what I call a “signed logarithm”. A signed logarithm takes the logarithm of the absolute value of the variable and multiplies by the appropriate sign. Values with absolute value less than one are mapped to zero. The difference between log and signed log are shown in figure 2.
Figure 2 Signed log lets you visualize non-positive data on a logarithmic scale
Clearly this isn’t useful if values below unit magnitude are important. But with many monetary variables (in US currency), values less than a dollar aren’t much different from zero (or one), for all practical purposes. So, for example, mapping account balances that are less than a dollar to $1 (the equivalent every account always having a minimum balance of one dollar) is probably okay.
Once you’ve got the data suitably cleaned and transformed, you are almost ready to start the modeling stage.
Summary
At some point, you will have data that is as good quality as you can make it. You've fixed problems with missing data, and performed any needed transformations. You are ready to go on the modeling stage. Remember, though, that data science is an iterative process. You may discover during the modeling process that you have to do additional data cleaning or transformation.
(Guest post by Achim Zeileis) Development of the R package exams for automatic generation of (statistical) exams in R started in 2006 and version 1 was published in JSS by Grün and Zeileis (2009). It was based on standalone Sweaveexercises, that can be combined into exams, and then rendered into different kinds of PDF output (exams, solutions, self-study materials, etc.). Now, a major revision of the package has been released that extends the capabilities and adds support for learning management systems. It is still based on the same type of Sweave files for each exercise but can also render them into output formats like HTML (with various options for displaying mathematical content) and XML specifications for online exams in learning management systems such as Moodle or OLAT. Supplementary files such as graphics or data are handled automatically. Here, I give a brief overview of the new capabilities. A detailed discussion is in the working paper by Zeileis, Umlauf, and Leisch (2012) that is also contained in the package as a vignette. Continue reading “Generation of E-Learning Exams in R for Moodle, OLAT, etc.”
In the past two years, a growing community of R users (and statisticians in general) have been participating in two major Question-and-Answer websites:
Stat over flow (which will soon move to a new domain, no worries, I’ll write about it once it happens)
In that time, several long (and fascinating) discussion threads where started, reflecting on tips and best practices for managing a statistical analysis project. They are:
On the last thread in the list, the user chl, has started with trying to compile all the tips and suggestions together. And with his permission, I am now republishing it here. I encourage you to contribute from your own experience (either in the comments, or by answering to any of the threads I’ve linked to)