I’m excited to announce that heatmaply version 1.0.0 has been published to CRAN! (getting started vignette is available here)
What is heatmaply?
heatmaply is an R package for easily creating interactive cluster heatmaps that can be shared online as a stand-alone HTML file. Interactivity includes a tooltip display of values when hovering over cells, as well as the ability to zoom in to specific sections of the figure from the data matrix, the side dendrograms, or annotated labels.
The package aims to be compatible with gplots::heatmap.2 so you could take code written for it and just change the heatmap.2 command to be heatmaply, and get the interactive version of the plot (although with slightly different, improved, defaults for colors and dendrogram ordering). Thanks to the synergistic relationship between heatmaply and other R packages, the user is empowered by a refined control over the statistical and visual aspects of the heatmap layout.
What makes heatmaply great?
The change from version 0.16.0 to version 1.0.0 is to indicate the maturity of the package. It is to reflect the following facts:
Summary:heatmaply is an R package for easily creating interactive cluster heatmaps that can be shared online as a stand-alone HTML file. Interactivity includes a tooltip display of values when hovering over cells, as well as the ability to zoom in to specific sections of the figure from the data matrix, the side dendrograms, or annotated labels. Thanks to the synergistic relationship between heatmaply and other R packages, the user is empowered by a refined control over the statistical and visual aspects of the heatmap layout.
Availability: The heatmaply package is available under the GPL-2 Open Source license. It comes with a detailed vignette, and is freely available from: http://cran.r-project.org/package=heatmaply
Cheatsheets are currently built and used exclusivley as a teaching tool. We want to try and change this and produce a cheat sheet that gives a roadmap to build a known product, but also is built as a function so users can input data into it to make the cheatsheet more personalized. This gives a versalility of a consistent format that people can share with each other, but has the added value of conveying a message through data driven visual changes.
Example
ggplot2 themes
The ggplot2 theme object is an amazing object you can specify nearly any part of the plot that is not conditonal on the data. What sets the theme object apart is that its structure is consistent, but the values in it change. In addition to change a theme it is a single function that too has a consistent call. The reoccuring challenge for users is to remember all the options that can be used in the theme call (there are approximately 220 unique options to calibrate at last count) or bookmark the help page for the theme and remember how you deciphered it last time.
This becomes a problem to pass all the information of the theme to someone who does not know what the values are set in your theme and attach instructions on it to let them recreate it without needing to open any web pages.
In writing the library ggedit we tried to make it easy to edit your theme so you don’t have to know too much about ggplots to make a large number of changes at once, for a quick clip see here. We had to make it easy to track those changes for people who are not versed in R, and plot.theme() was the outcome. In short think of the theme as a lot of small images that are combined to create a singel portrait.
Last week the updated version of ggedit was presented in RStudio::conf2017. First, a BIG thank you to the whole RStudio team for a great conference and being so awesome to answer the insane amount of questions I had (sorry!). For a quick intro to the package see the previous post.
ggplot2 has become the standard of plotting in R for many users. New users, however, may find the learning curve steep at first, and more experienced users may find it challenging to keep track of all the options (especially in the theme!).
ggedit is a package that helps users bridge the gap between making a plot and getting all of those pesky plot aesthetics just right, all while keeping everything portable for further research and collaboration.
ggedit is powered by a Shiny gadget where the user inputs a ggplot plot object or a list of ggplot objects. You can run ggedit directly from the console from the Addin menu within RStudio.
Guest post by JohnBellettiere,VincentBerardi,SantiagoEstrada
The Goal
To visually explore relations between two related variables and an outcome using contour plots. We use thecontourfunction in Base R to produce contour plots that are well-suited for initial investigations into three dimensional data. We then develop visualizations using ggplot2 to gain more control over the graphical output. We also describe several data transformations needed to accomplish this visual exploration.
Guest post by Gergely Daróczi. If you like this content, you can buy the full 396 paged e-book for 5 USD until January 8, 2016 as part of Packt’s “$5 Skill Up Campaign” at https://bit.ly/mastering-R
Feature extraction tends to be one of the most important steps in machine learning and data science projects, so I decided to republish a related short section from my intermediate book on how to analyze data with R. The 9th chapter is dedicated to traditional dimension reduction methods, such as Principal Component Analysis, Factor Analysis and Multidimensional Scaling — from which the below introductory examples will focus on that latter.
Multidimensional Scaling (MDS) is a multivariate statistical technique first used in geography. The main goal of MDS it is to plot multivariate data points in two dimensions, thus revealing the structure of the dataset by visualizing the relative distance of the observations. Multidimensional scaling is used in diverse fields such as attitude study in psychology, sociology or market research.
Although the MASS package provides non-metric methods via the isoMDS function, we will now concentrate on the classical, metric MDS, which is available by calling the cmdscale function bundled with the stats package. Both types of MDS take a distance matrix as the main argument, which can be created from any numeric tabular data by the dist function.
But before such more complex examples, let’s see what MDS can offer for us while working with an already existing distance matrix, like the built-in eurodist dataset:
> as.matrix(eurodist)[1:5, 1:5]
Athens Barcelona Brussels Calais Cherbourg
Athens 0 3313 2963 3175 3339
Barcelona 3313 0 1318 1326 1294
Brussels 2963 1318 0 204 583
Calais 3175 1326 204 0 460
Cherbourg 3339 1294 583 460 0
The above subset (first 5-5 values) of the distance matrix represents the travel distance between 21 European cities in kilometers. Running classical MDS on this example returns:
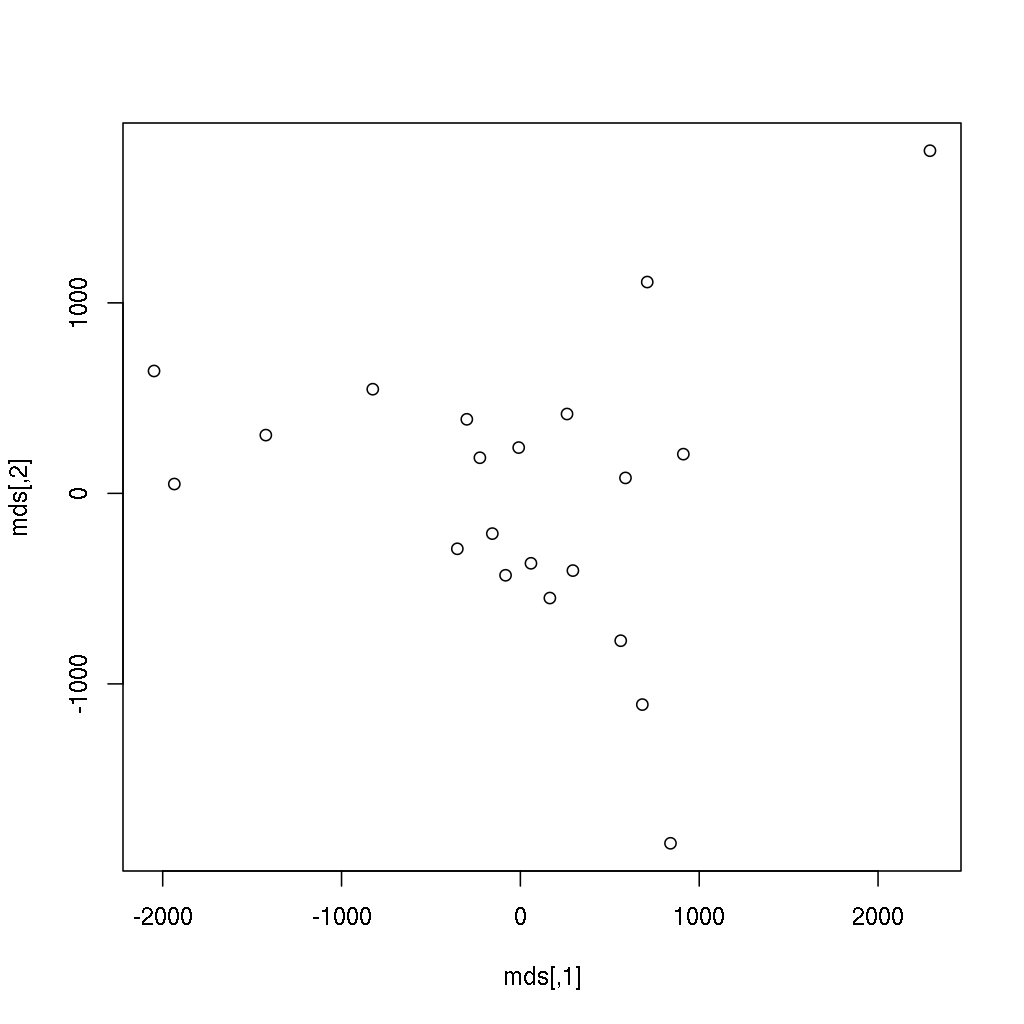
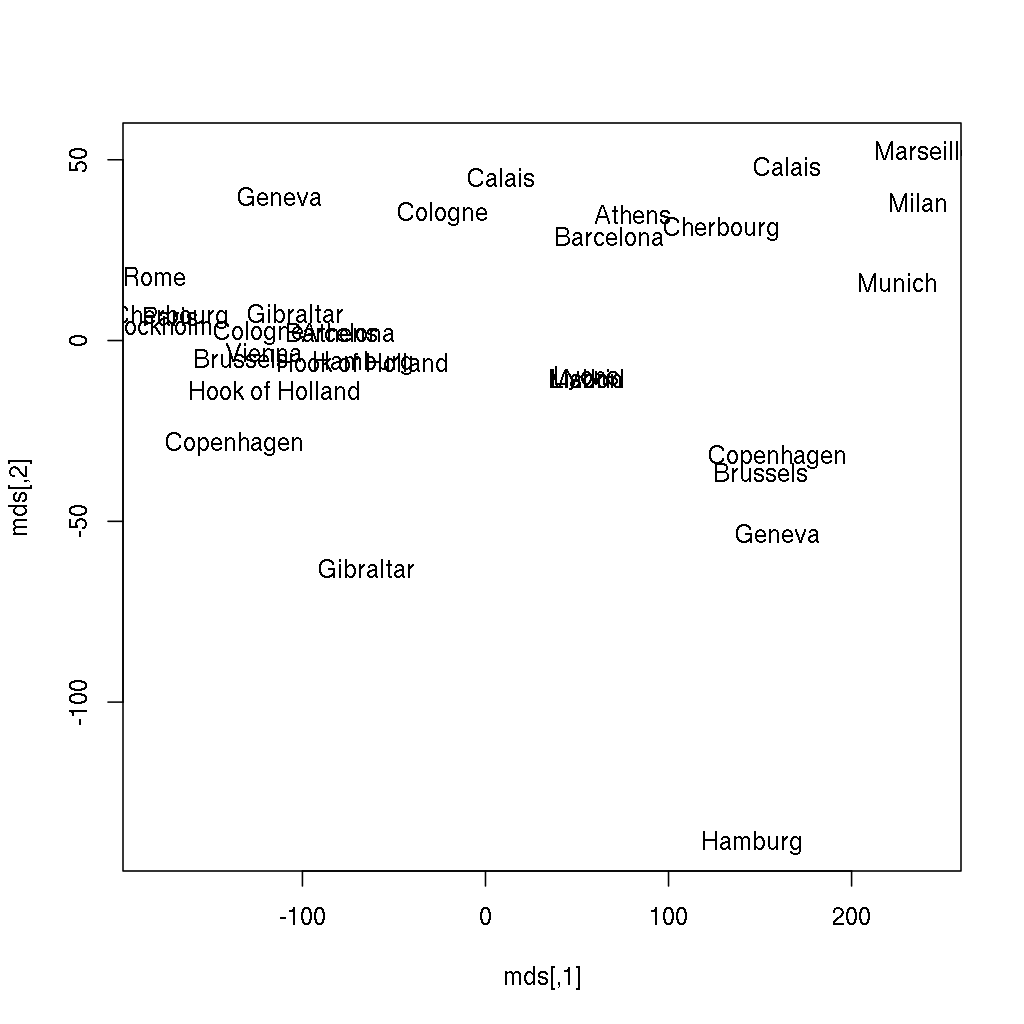
> (mds <- cmdscale(eurodist))
[,1] [,2]
Athens 2290.2747 1798.803
Barcelona -825.3828 546.811
Brussels 59.1833 -367.081
Calais -82.8460 -429.915
Cherbourg -352.4994 -290.908
Cologne 293.6896 -405.312
Copenhagen 681.9315 -1108.645
Geneva -9.4234 240.406
Gibraltar -2048.4491 642.459
Hamburg 561.1090 -773.369
Hook of Holland 164.9218 -549.367
Lisbon -1935.0408 49.125
Lyons -226.4232 187.088
Madrid -1423.3537 305.875
Marseilles -299.4987 388.807
Milan 260.8780 416.674
Munich 587.6757 81.182
Paris -156.8363 -211.139
Rome 709.4133 1109.367
Stockholm 839.4459 -1836.791
Vienna 911.2305 205.930
These scores are very similar to two principal components (discussed in the previous, Principal Component Analysis section), such as running prcomp(eurodist)$x[, 1:2]. As a matter of fact, PCA can be considered as the most basic MDS solution.
Anyway, we have just transformed (reduced) the 21-dimensional space into 2 dimensions, which can be plotted very easily — unlike the original distance matrix with 21 rows and 21 columns:
> plot(mds)
Does it ring a bell? If not yet, the below image might be more helpful, where the following two lines of code also renders the city names instead of showing anonymous points:
p.s.: Yes – this presentation is very similar, although not identical, to the one I gave at useR2015. For example, I mention the new bioinformatics paper on dendextend.
Summary:dendextend is an R package for creating and comparing visually appealing tree diagrams. dendextend provides utility functions for manipulating dendrogram objects (their color, shape, and content) as well as several advanced methods for comparing trees to one another (both statistically and visually). As such, dendextend offers a flexible framework for enhancing R’s rich ecosystem of packages for performing hierarchical clustering of items.