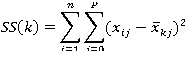(Guest post by Matt Sundquist on a lovely new service which is pro-actively supporting an API for R)
The Plotly R graphing library allows you to create and share interactive, publication-quality plots in your browser. Plotly is also built for working together, and makes it easy to post graphs and data publicly with a URL or privately to collaborators.
In this post, we’ll demo Plotly, make three graphs, and explain sharing. As we’re quite new and still in our beta, your help, feedback, and suggestions go a long way and are appreciated. We’re especially grateful for Tal’s help and the chance to post.
>library(plotly)
>response = signup (username = 'username', email= 'youremail')
…
Thanks for signing up to plotly!
Your username is: MattSundquist
Your temporary password is: pw. You use this to log into your plotly account at https://plot.ly/plot. Your API key is: “API_Key”. You use this to access your plotly account through the API.
To get started, initialize a plotly object with your username and api_key, e.g.
>>> p <- plotly(username="MattSundquist", key="API_Key")
Then, make a graph!
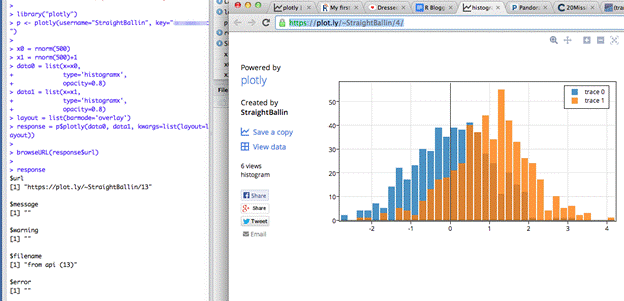
>>> res <- p$plotly(c(1,2,3), c(4,2,1))
And we’re up and running! You can change and access your password and key in your homepage.
The script makes a graph. Use the RStudio viewer or add “browseURL(response$url)” to your script to avoid copy and paste routines of your URL and open the graph directly.
In R’s partitioning approach, observations are divided into K groups and reshuffled to form the most cohesive clusters possible according to a given criterion. There are two methods—K-means and partitioning around mediods (PAM). In this article, based on chapter 16 of R in Action, Second Edition, author Rob Kabacoff discusses K-means clustering.
In R’s partitioning approach, observations are divided into K groups and reshuffled to form the most cohesive clusters possible according to a given criterion. There are two methods—K-means and partitioning around mediods (PAM). In this article, based on chapter 16 of R in Action, Second Edition, author Rob Kabacoff discusses K-means clustering.
Until Aug 21, 2013, you can buy the book: R in Action, Second Edition with a 44% discount, using the code: “mlria2bl”.
K-means clustering
The most common partitioning method is the K-means cluster analysis. Conceptually, the K-means algorithm:
Selects K centroids (K rows chosen at random)
Assigns each data point to its closest centroid
Recalculates the centroids as the average of all data points in a cluster (i.e., the centroids are p-length mean vectors, where p is the number of variables)
Assigns data points to their closest centroids
Continues steps 3 and 4 until the observations are not reassigned or the maximum number of iterations (R uses 10 as a default) is reached.
Implementation details for this approach can vary.
R uses an efficient algorithm by Hartigan and Wong (1979) that partitions the observations into k groups such that the sum of squares of the observations to their assigned cluster centers is a minimum. This means that in steps 2 and 4, each observation is assigned to the cluster with the smallest value of:
Where k is the cluster,xij is the value of the jth variable for the ith observation, and xkj-bar is the mean of the jth variable for the kth cluster.
Disclaimer: This post is not intended to be a comprehensive review, but more of a “getting started guide”. If I did not mention an important tool or package I apologize, and invite readers to contribute in the comments.
Introduction
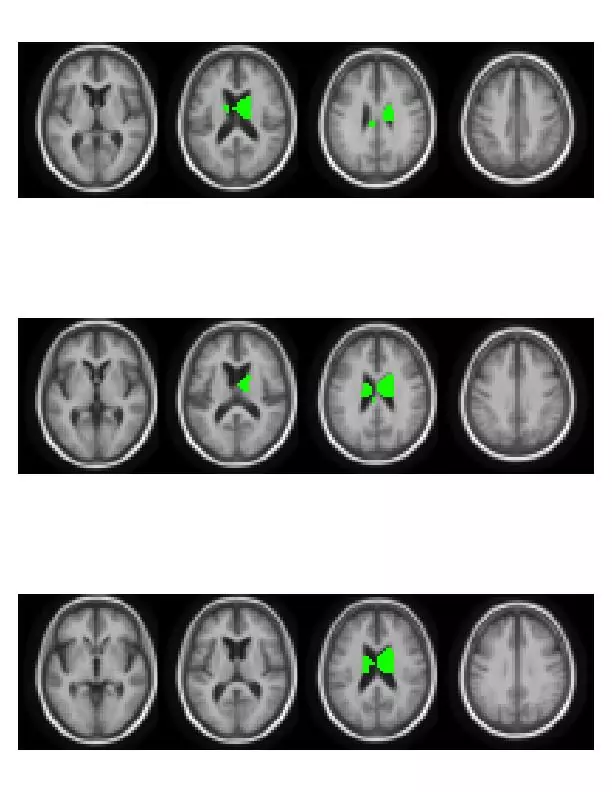
I have recently had the delight to participate in a “Brain Hackathon” organized as part of the OHBM2013 conference. Being supported by Amazon, the hackathon participants were provided with Amazon credit in order to promote the analysis using Amazon’s Web Services (AWS). We badly needed this computing power, as we had 14*109 p-values to compute in order to localize genetic associations in the brain leading to Figure 1.
Figure 1- Brain volumes significantly associated to genotype.
While imaging genetics is an interesting research topic, and the hackathon was a great idea by itself, it is the AWS I wish to present in this post. Starting with the conclusion:
Storing your data and analyzing it on the cloud, be it AWS, Azure, Rackspace or others, is a quantum leap in analysis capabilities. I fell in love with my new cloud powers and I strongly recommend all statisticians and data scientists get friendly with these services. I will also note that if statisticians do not embrace these new-found powers, we should not be surprised if data analysis becomes synonymous with Machine Learning and not with Statistics (if you have no idea what I am talking about, read this excellent post by Larry Wasserman).
As motivation for analysis in the cloud consider:
The ability to do your analysis from any device, be it a PC, tablet or even smartphone.
The ability to instantaneously augment your CPU and memory to any imaginable configuration just by clicking a menu. Then scaling down to save costs once you are done.
The ability to instantaneously switch between operating systems and system configurations.
The ability to launch hundreds of machines creating your own cluster, parallelizing your massive job, and then shutting it down once done.
Here is a quick FAQ before going into the setup stages.
What are the top 100 (most downloaded) R packages in 2013? Thanks to the recent release of RStudio of their “0-cloud” CRAN log files (but without including downloads from the primary CRAN mirror or any of the 88 other CRAN mirrors), we can now answer this question (at least for the months of Jan till May)!
By relying on the nice code that Felix Schonbrodt recently wrote for tracking packages downloads, I have updated my installr R package with functions that enables the user to easily download and visualize the popularity of R packages over time. In this post I will share some nice plots and quick insights that can be made from this great data. The code for this analysis is given at the end of this post.
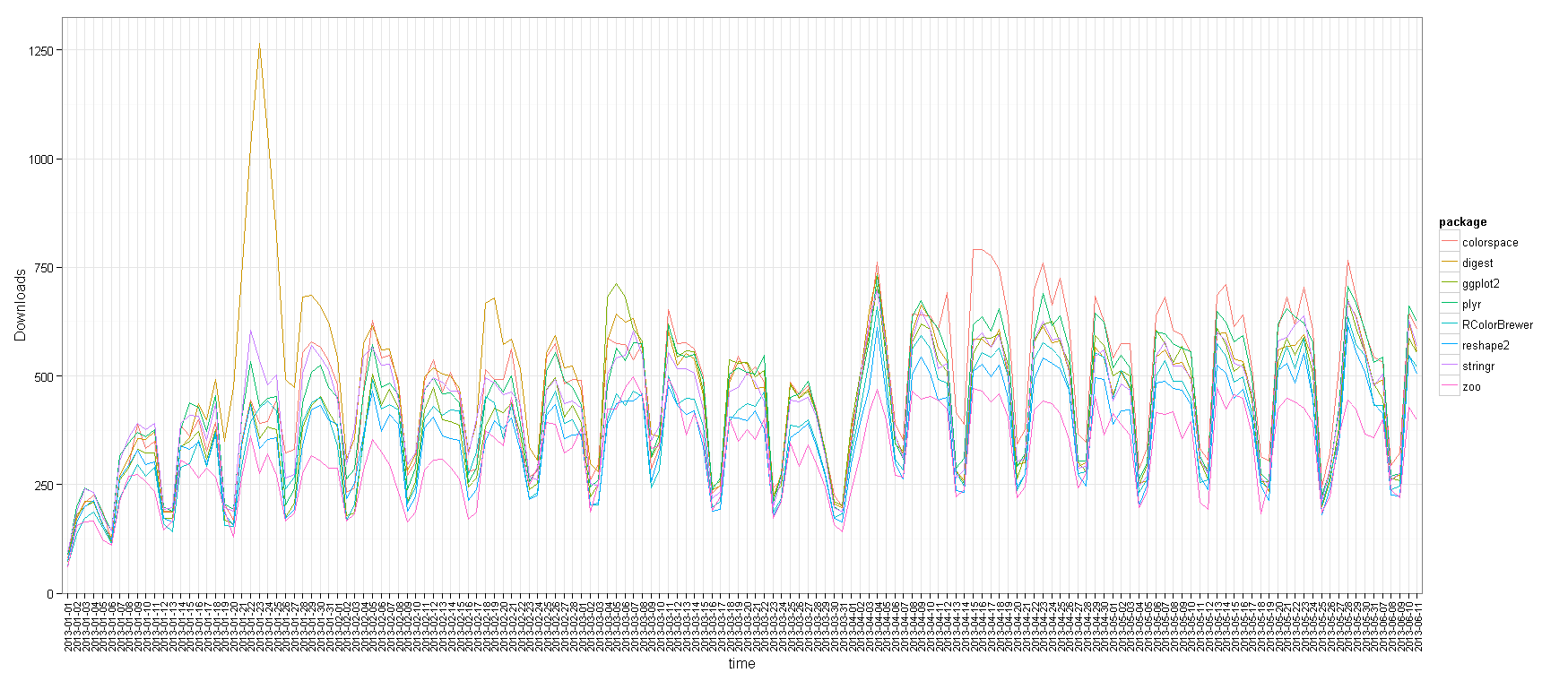
Top 8 most downloaded R packages – downloads over time
Let’s first have a look at the number of downloads per day for these 5 months, of the top 8 most downloaded packages (click the image for a larger version):
We can see the strong weekly seasonality of the downloads, with Saturday and Sunday having much fewer downloads than other days. This is not surprising since we know that the countries which uses R the most have these days as rest days (see James Cheshire’s world map of R users). It is also interesting to note how some packages had exceptional peaks on some dates. For example, I wonder what happened on January 23rd 2013 that the digest package suddenly got so many downloads, or that colorspace started getting more downloads from April 15th 2013.
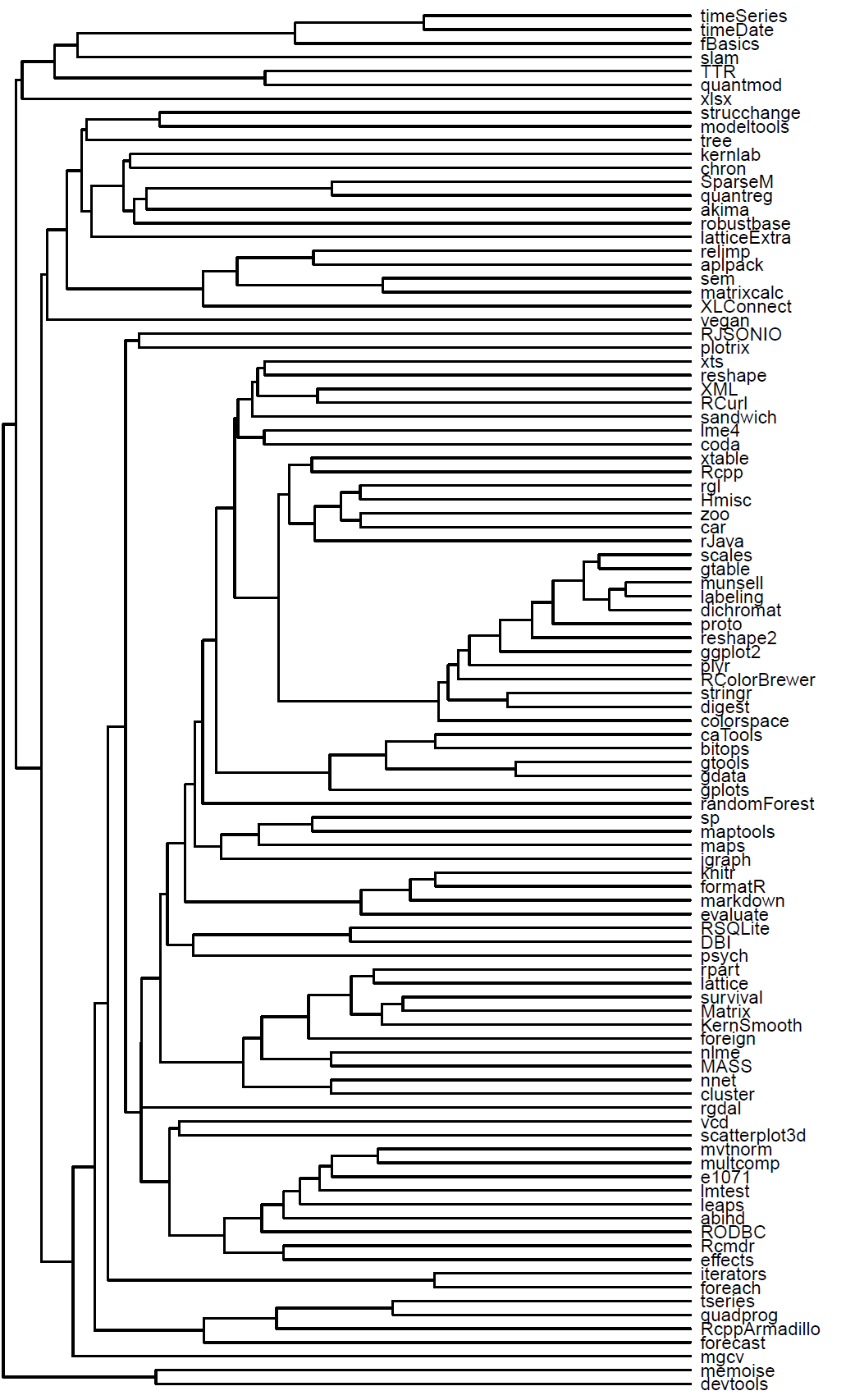
“Family tree” of the top 100 most downloaded R packages
We can extract from this data the top 100 most downloaded R packages. Moreover, we can create a matrix showing for each package which of our unique ids (censored IP addresses), has downloaded which package. Using this indicator matrix, we can thing of the “similarity” (or distance) between each two packages, and based on that we can create a hierarchical clustering of the packages – showing which packages “goes along” with one another.
With this analysis, you can locate package on the list which you often use, and then see which other packages are “related” to that package. If you don’t know that package – consider having a look at it – since other R users are clearly finding the two packages to be “of use”.
Such analysis can (and should!) be extended. For example, we can imagine creating a “suggest a package” feature based on this data, utilizing the package which you use, the OS that you use, and other parameters. But such coding is beyond the scope of this post.
Here is the “family tree” (dendrogram) of related packages:
To make it easier to navigate, here is a table with links to the top 100 R packages, and their links:
The new version includes various bug fixes (as can be seen in the NEWS file) and new functions and features. The most user visible feature is that from now on, whenever loading installr in the Rgui, it will add a new menu-bar for updating your R version (the menu is removed when the package is detached).
When choosing to update R, a new GUI based system will guide you step by step through the updating process. It will first check if a newer version of R is available, if so, it will offer to show the latest NEWS of that release, download and install the new version, and copy/move your packages from the previous library folder, to the one in the new installation. If you have a global library folder, you can simply stop the updating once your new R is installed, and continue as you would otherwise (in the future, I intend to update the package to also allow it to deal with people using a global library folder).
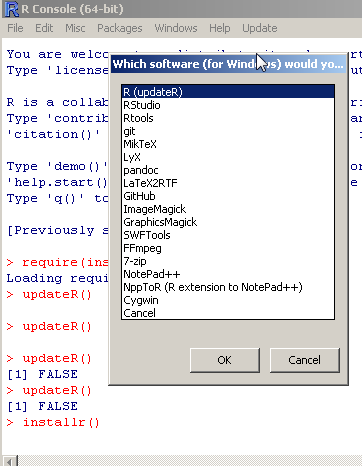
Another new feature is the “installr()” function (which can also be run through the menubar), running it will open a window with a list of software you can download and install using the installr package (From Rtools and RStudio to pandoc and MikTeX).
I hope you’ll enjoy this new release, and as always – please let me know in the comments (or via e-mail) if you come across any bugs or have suggestions for new features.
The followings introductory post is intended for new users of R. It deals with the restructuring of data: what it is and how to perform it using base R functions and the {reshape} package. This is a guest article by Dr. Robert I. Kabacoff, the founder of (one of) the first online R tutorials websites: Quick-R. Kabacoff […]
The followings introductory post is intended for new users of R. It deals with the restructuring of data: what it is and how to perform it using base R functions and the {reshape} package.
This is a guest article by Dr. Robert I. Kabacoff, the founder of (one of) the first online R tutorials websites: Quick-R. Kabacoff has recently published the book ”R in Action“, providing a detailed walk-through for the R language based on various examples for illustrating R’s features (data manipulation, statistical methods, graphics, and so on…). The previous guest post by Kabacoff introduced data.frame objects in R.
For readers of this blog, there is a 38% discount off the “R in Action” book (as well as all other eBooks, pBooks and MEAPs at Manning publishing house), simply by using the code rblogg38 when reaching checkout.
Let us now talk about the Aggregation and Restructuring of data in R:
Aggregation and Restructuring
R provides a number of powerful methods for aggregating and reshaping data. When you aggregate data, you replace groups of observations with summary statistics based on those observations. When you reshape data, you alter the structure (rows and columns) determining how the data is organized. This article describes a variety of methods for accomplishing these tasks.
We’ll use the mtcars data frame that’s included with the base installation of R. This dataset, extracted from Motor Trend magazine (1974), describes the design and performance characteristics (number of cylinders, displacement, horsepower, mpg, and so on) for 34 automobiles. To learn more about the dataset, see help(mtcars).
Transpose
The transpose (reversing rows and columns) is perhaps the simplest method of reshaping a dataset. Use the t() function to transpose a matrix or a data frame. In the latter case, row names become variable (column) names. An example is presented in the next listing.
Listing 1 uses a subset of the mtcars dataset in order to conserve space on the page. You’ll see a more flexible way of transposing data when we look at the reshape package later in this article.
Aggregating data
It’s relatively easy to collapse data in R using one or more by variables and a defined function. The format is
1
aggregate(x, by, FUN)
where x is the data object to be collapsed, by is a list of variables that will be crossed to form the new observations, and FUN is the scalar function used to calculate summary statistics that will make up the new observation values.
As an example, we’ll aggregate the mtcars data by number of cylinders and gears, returning means on each of the numeric variables (see the next listing).
Listing 2 Aggregating data
1
2
3
4
5
6
7
8
9
10
11
12
13
>options(digits=3)>attach(mtcars)> aggdata <-aggregate(mtcars, by=list(cyl,gear), FUN=mean, na.rm=TRUE)> aggdata
Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
14321.54120973.702.4620.01.00.0031.0026319.862421082.923.3419.81.00.0031.0038315.183581943.124.1017.10.00.0033.0844426.94103764.112.3819.61.00.7541.5056419.861641163.913.0917.70.50.5044.0064528.241081024.101.8316.80.51.0052.0076519.761451753.622.7715.50.01.0056.0088515.483263003.883.3714.60.01.0056.00
In these results, Group.1 represents the number of cylinders (4, 6, or and Group.2 represents the number of gears (3, 4, or 5). For example, cars with 4 cylinders and 3 gears have a mean of 21.5 miles per gallon (mpg).
When you’re using the aggregate() function , the by variables must be in a list (even if there’s only one). You can declare a custom name for the groups from within the list, for instance, using by=list(Group.cyl=cyl, Group.gears=gear).
The function specified can be any built-in or user-provided function. This gives the aggregate command a great deal of power. But when it comes to power, nothing beats the reshape package.
The reshape package
The reshape package is a tremendously versatile approach to both restructuring and aggregating datasets. Because of this versatility, it can be a bit challenging to learn.
We’ll go through the process slowly and use a small dataset so that it’s clear what’s happening. Because reshape isn’t included in the standard installation of R, you’ll need to install it one time, using install.packages(“reshape”).
Basically, you’ll “melt” data so that each row is a unique ID-variable combination. Then you’ll “cast” the melted data into any shape you desire. During the cast, you can aggregate the data with any function you wish. The dataset you’ll be working with is shown in table 1.
Table 1 The original dataset (mydata)
ID
Time
X1
X2
1
1
5
6
1
2
3
5
2
1
6
1
2
2
2
4
In this dataset, the measurements are the values in the last two columns (5, 6, 3, 5, 6, 1, 2, and 4). Each measurement is uniquely identified by a combination of ID variables (in this case ID, Time, and whether the measurement is on X1 or X2). For example, the measured value 5 in the first row is uniquely identified by knowing that it’s from observation (ID) 1, at Time 1, and on variable X1.
Melting
When you melt a dataset, you restructure it into a format where each measured variable is in its own row, along with the ID variables needed to uniquely identify it. If you melt the data from table 1, using the following code
Note that you must specify the variables needed to uniquely identify each measurement (ID and Time) and that the variable indicating the measurement variable names (X1 or X2) is created for you automatically.
Now that you have your data in a melted form, you can recast it into any shape, using the cast() function.
Casting
The cast() function starts with melted data and reshapes it using a formula that you provide and an (optional) function used to aggregate the data. The format is
1
newdata <- cast(md, formula, FUN)
Where md is the melted data, formula describes the desired end result, and FUN is the (optional) aggregating function. The formula takes the form
1
rowvar1 + rowvar2 + … ~ colvar1 + colvar2 + …
In this formula, rowvar1 + rowvar2 + … define the set of crossed variables that define the rows, and colvar1 + colvar2 + … define the set of crossed variables that define the columns. See the examples in figure 1. (click to enlarge the image)
Figure 1 Reshaping data with the melt() and cast() functions
Because the formulas on the right side (d, e, and f) don’t include a function, the data is reshaped. In contrast, the examples on the left side (a, b, and c) specify the mean as an aggregating function. Thus the data are not only reshaped but aggregated as well. For example, (a) gives the means on X1 and X2 averaged over time for each observation. Example (b) gives the mean scores of X1 and X2 at Time 1 and Time 2, averaged over observations. In (c) you have the mean score for each observation at Time 1 and Time 2, averaged over X1 and X2.
As you can see, the flexibility provided by the melt() and cast() functions is amazing. There are many times when you’ll have to reshape or aggregate your data prior to analysis. For example, you’ll typically need to place your data in what’s called long format resembling table 2 when analyzing repeated measures data (data where multiple measures are recorded for each observation).
Summary
Chapter 5 ofR in Action reviews many of the dozens of mathematical, statistical, and probability functions that are useful for manipulating data. In this article, we have briefly explored several ways of aggregating and restructuring data.
This article first appeared as chapter 5.6 from the “R in action“ book, and is published with permission from Manning publishing house. Other books in this serious which you might be interested in are (see the beginning of this post for a discount code):